Popis principu funkce
Tento text pojednává o obecném principu stojícímu za Markovovými řetězci a generováním textu z nich. Implementaci tohoto obecného principu se věnuje oddíl Popis implementace.
Markovův řetězec
Stacionární Markovův řetězec (dále Markovův řetězec) je uspořádaná posloupnost $n$ náhodných proměnných $X_1, X_2, \ldots, X_n$.[1] Ty mohou nabývat jedné z konečné množiny hodnot; hodnotu náhodné proměnné $X_i$ budeme značit $x_i$ a nazveme ji stav v okamžiku $i$. Množinu všech možných stavů označíme jako stavový prostor. Pro všechny $X_i$ ($i>1$) platí, že:
Jinými slovy, stav v okamžiku $i$ závisí pouze na stavu v předchozím okamžiku.
Tato takzvaná markovovská vlastnost dala Markovově řetězci jeho jméno. Dovoluje nám znázornit celý systém orientovaným grafem, ve kterém vrcholy představují jednotlivé stavy systému a hrany mají hodnoty pravděpodobností přechodů z jednoho stavu do druhého. Pro úplnost je dobré dodat, že Markovův řetězec se dá kromě grafu popsat také maticí pravděpodobností přechodu $P$, kde $p_{ij}$ označuje pravděpodobnost přechodu ze stavu $i$ do stavu $j$.
Pojem Markovův řetězec se dá dále rozšířit o takzvaný řád. Stav v okamžiku $i$ v Markovově řetězci o řádu $r$ závisí na všech stavech $X_{i-1}, X_{i-2}, \ldots, X_{i-r}$.
Generování textu
Proces generování textu pomocí Markovova řetězce se skládá ze dvou částí:
- Vytvoření řetězce na základě vstupního textu.
- Procházení vytvořeným grafem a postupné tvoření výstupu.
Vytvoření grafu
Daný text je před modelováním nutné rozložit na tokeny: většinou slova, případně někdy jednotlivé znaky.
Text se poré zpravidla modeluje řetězcem o řádu 2, 3, nebo 4; obecně $k$. Stavový prostor bude tvořen všemi $k$-ticemi tokenů, které se vyskytují ve vstupním textu: to budou vrcholy požadovaného grafu. Vyplatí se také nějak označit začátek a konec textu, třeba jako speciální stavy.
Hrany (a jejich hodnoty) pak budou udávat, s jakou pravděpodobností se vyskytuje jedna $k$-tice tokenů "za" jinou. Slovo "za" je v uvozovkách, neboť $k$-tice se překrývají a dvě následné $k$-tice se tedy liší pouze v jednom znaku.
Mějme vstupní text "ABABD". Markovův řetězec o řádu 2 tohoto textu by se dal grafem znázornit takto:
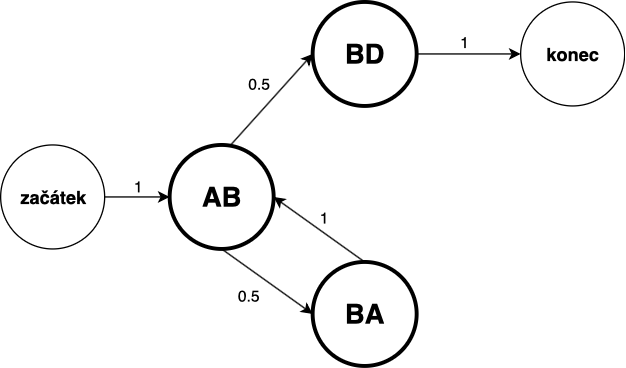
Procházení grafu
Pokud máme k dispozici graf, je generování textu už velice jednoduché: začneme na jednom z vrcholů označených jako začátek a pak se pohybujeme po hranách, dokud nenarazíme na vrchol konec. Po hranách se pohybujeme náhodně, přičemž hrany svými hodnotami ovlivňují rozložení pravděpodobností přesunu z jednoho stavu do druhého.
Pokud použijeme graf z minulého příkladu, generování textu by mohlo probíhat například takto:
začátek $\longrightarrow$ AB $\longrightarrow$ BA $\longrightarrow$ AB $\longrightarrow$ BA $\longrightarrow$ AB $\longrightarrow$ BD $\longrightarrow$ konec
Výsledný text poté nebude prostým složením stavů, které jsme prošli (neboť ty se částečně překrývaly), ale bude vypadat takto: "ABABABD".
Existují také řetězce nestacionární, kterým se rozložení pravděpodobností mění ještě v závislosti na okamžiku $i$. Ty ale nejsou předmětem našeho zájmu, neboť slouží k modelování dynamičtějších systémů než je text.